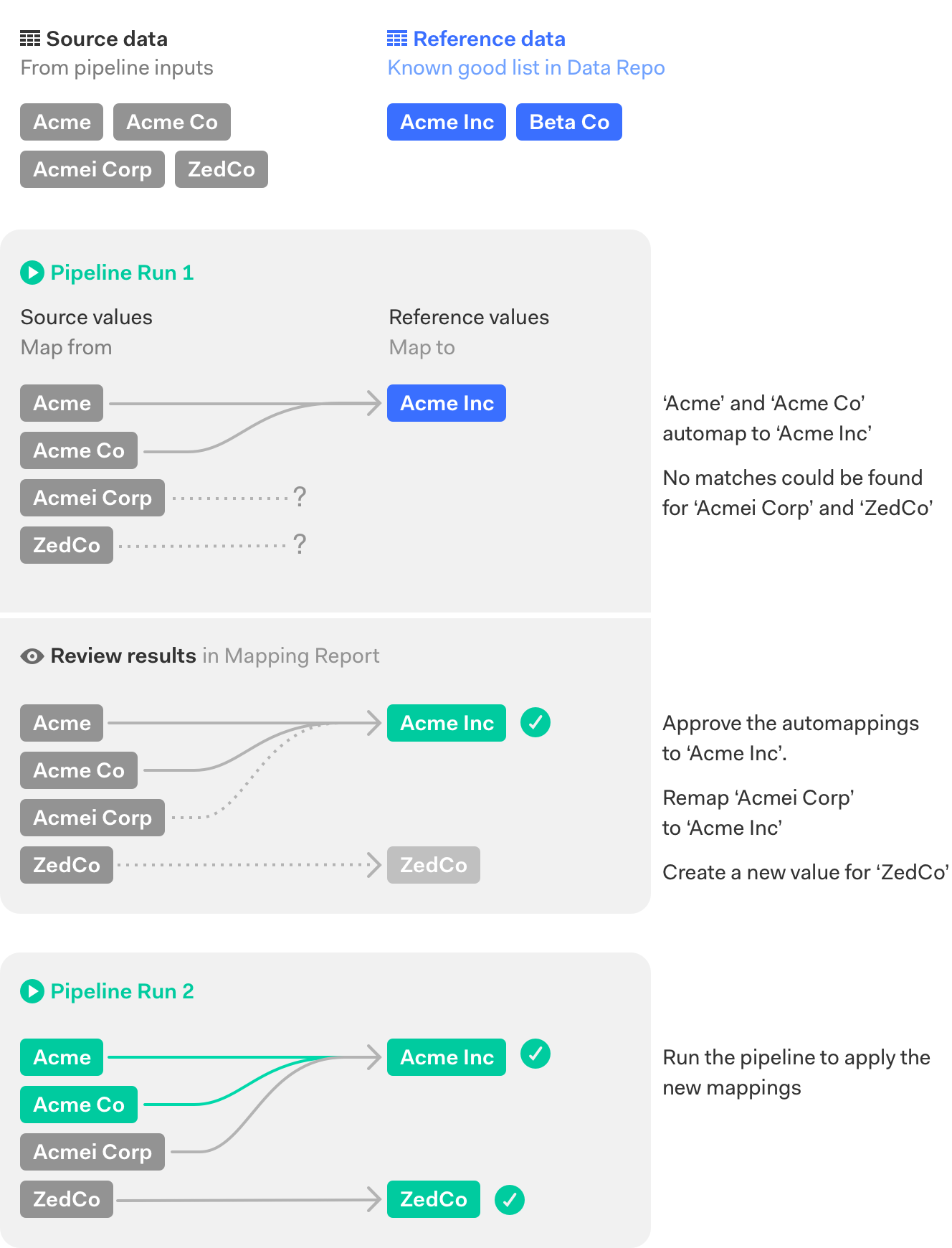
When cleansing a column of values, individually specifying mappings for large numbers of values can be time-consuming.
Automap values can help by automatically comparing
all of the source values to a known good set of values in a reference dataset, then mapping them to the best match,
determined by a similarity algorithm.
The automapping is performed when the pipeline is run and the resulting mappings can be reviewed,
approved and edited in a Mapping Report.
Automapping can be enabled in the Map Values operation. Got to Using Automap Values to learn more about how to get started.
Here's a short video we made showing how Automap Values can be used for company name cleansing.
Example: standardise company names
Reference datasets
Automap requires a set of known-good values it should attempt to map each of the source values to.
This is specified as a column in a reference dataset.
The reference dataset can be any dataset stored and shared in your Data Repo.
Match strength
Automap assesses the similarity of a value in the source dataset to each of the values in the reference dataset,
assigns a percentage match strength and selects the highest strength match to create the mapping.
Attempted matches with a strength of 0% will not be mapped and are treated as ‘Unmatched’.
Minimum match strength
A match strength threshold at which mappings are applied can be set.
For instance, you may not wish to map values where the match strength is below 50%.
Where the strength for a mapping is below this threshold, the value is treated as ‘Unmatched’.
Setting minimum match strength
The minimum match strength setting filters out matches below a specified threshold.
The optimum value for the useful minimum match strength will depend on the nature of
the source and reference datasets and the intended use case.
The first time you run Automap Values, setting a minimum match strength of 0% will produce
the full list of mappings from which a useful minimum match strength can be determined.
Unmatched values
Where a match could not be found, or the strength of the match was below the minimum match strength threshold,
the value is considered as ‘Unmatched’. Unmatched values are either left unaltered, or mapped to a default
value if desired (defined in the Map Values view).
Understanding Automap behaviour
Text similarity matching
Automap uses a text similarity algorithm to gauge match strength.
The algorithm assesses how similar two values are, purely by comparing their letters, numbers, punctuation and spaces.
Because the algorithm only compares similarity between text characters, matches might not seem intuitive when the meaning of the words is considered.
Consider an example where a source value is compared with two reference values:
Source value
Reference values
Match strength
Mapping result
Glass
Gas
42%
Gas
Glazing
27%
Although ‘Glass’ is more similar in meaning to ‘Glazing’ than ‘Gas’, ‘Gas’ has a stronger text similarity so is chosen.
If ‘Glazing’ is the desired mapping, the result can be remapped in the Mapping Report.
Case and space sensitivity
Automap is case-sensitive and will detect differences in space characters, such as trailing whitespace.
Adding some pre-processing steps to the reference and source data before Automapping may improve results:
Standardise case using the UPPER or PROPER functions in Calculate.
Use the TRIM function in Calculate to remove leading and trailing whitespace and repeated spaces between words.
Waypointing
Waypointing learns from previous mappings that have been approved or remapped to another value to inform the automapping of similar values.
For example, if ‘Timber’ is mapped to ‘Wood’ and approved, the similar value ‘Timbr’ is likely to map to ‘Wood’
in the next pipeline run. For more details, see Waypointing.
Manual mappings
Automap will not attempt to map source values which have already been mapped manually in the Map Values view.
Manual mappings are shown in the Mapping Report.
Variance in mapping results between runs
Quantemplate’s matching algorithm may be subject to updates and improvements.
Therefore for exactly the same source and reference data, automapping results could potentially vary over time.
Creating waypoints by approving mappings may also produce different results.
Once a mapping is approved or remapped values it will not affected by changes to automapping results.
Data sizes and run times
Run times increase according to the size of both the source and reference datasets.
You may experience long run times if both these datasets are large. Using context columns to reduce the number of potential matches may improve run times.
Only use one Automap Values per Stage
Automap values is a highly resource intensive operation.
To ensure optimum performance, there should be no more than one Automap Values operation in a Stage.
If you need to use mulitple Automap Values operations, put them in individual stages.
Reference dataset sizes
With advanced notice, Automap Values can use reference dataset sizes of up to 24m rows.
If you need to use a large reference dataset (>5m rows), please contact support@quantemplate.com,
so we can arrange scaled-up performance for you.
Context columns
Adding context columns allows you to distinguish similar values in your source column which should be
mapped to different entries in your reference data, based on the value in the context column.
Context columns comprise a column in the source data and an equivalent column in the reference data.
Automap will only attempt to map a source data value to a reference data value when the corresponding values in the context columns match exactly.
There can be up to three pairs of context columns. For each source value, all values across the source context
columns must match the values in the reference context columns for an automapping to be applied.
Example
In this example, the source data contains the same company name ‘InsurRe’ for two regional offices, US and UK.
Source data
Insurer
Region
InsurRe
UK
InsurRe
US
Reference data
Insurer
Region
InsurRe UK
UK
InsurRe US
US
If Automap only compares the Insurer column in the source and reference datasets,
it is unable to distinguish the two ‘InsurRe’ offices, so they are both mapped to ‘InsureRe UK’,
which is incorrect for the US office:
Results
Insurer
Source / Map from
Mapped Insurer
Reference / Map to
Region
Ignored
InsurRe UK
InsurRe UK
UK
InsurRe US
InsurRe UK
US
Because the values in ‘Region’ differ, adding it as a context column allows Automap to differentiate
the two offices and apply the correct mapping: