
The Regex operation allows you to find data matching a certain pattern which can then be extracted or changed. For example:
Patterns are defined using a language known as 'Regular Expressions', commonly called Regexes.
RIGHT(CONCATENATE("00000", 'Column-name'), 5)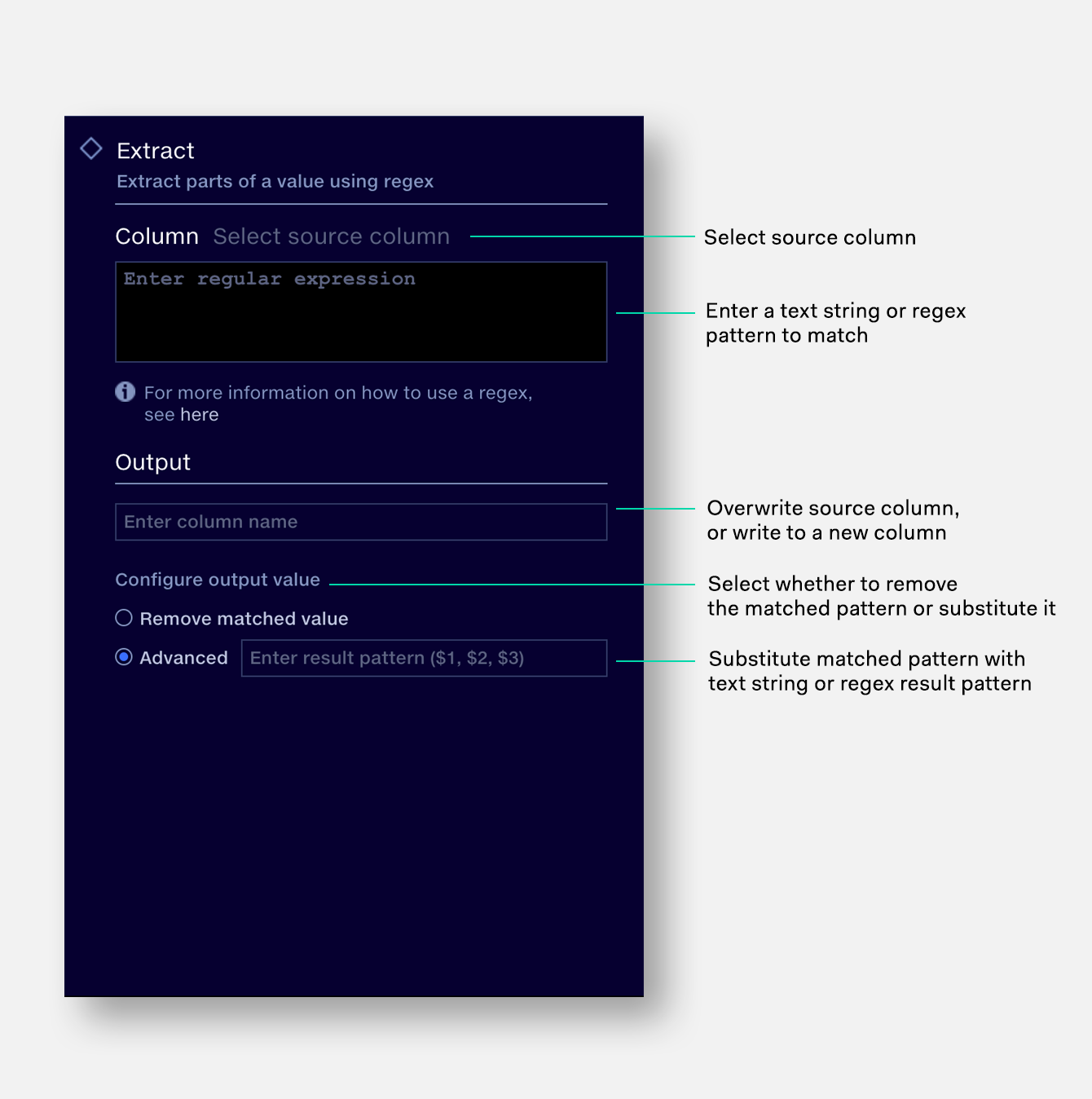
Select the source column to search.
Enter the search term or regex pattern.
Either name a new output column, or select the source column to overwrite it. If no column name is entered, an unnamed column will be created.
To remove regex matches, select ‘Remove matched value’.
To replace regex matches select ‘Advanced’ and enter a text string or a result pattern
(e.g. $1, $2, $3).
Enter the search pattern in the Regex field. This could be a specific sequence of text or numbers, such as the word ‘Rd’, though this is usually better dealt with using the Substitute function in Calculate.
The Regex operation is best used to search for patterns, using the Regular Expressions syntax. For example:
See the Syntax reference section for details and examples of the most commonly used Regex syntax.
Once a pattern has been matched, it can be either be removed, replaced, modified or repeated. The result can overwrite the source column or can be written to a new column. The $ symbol is used to reference groups within the regex pattern.
We want to find the building number from a column of addresses and extract it to a new column. We can do this by writing a regex to identify any sequence of numbers at the start of an address.
^(\d+).+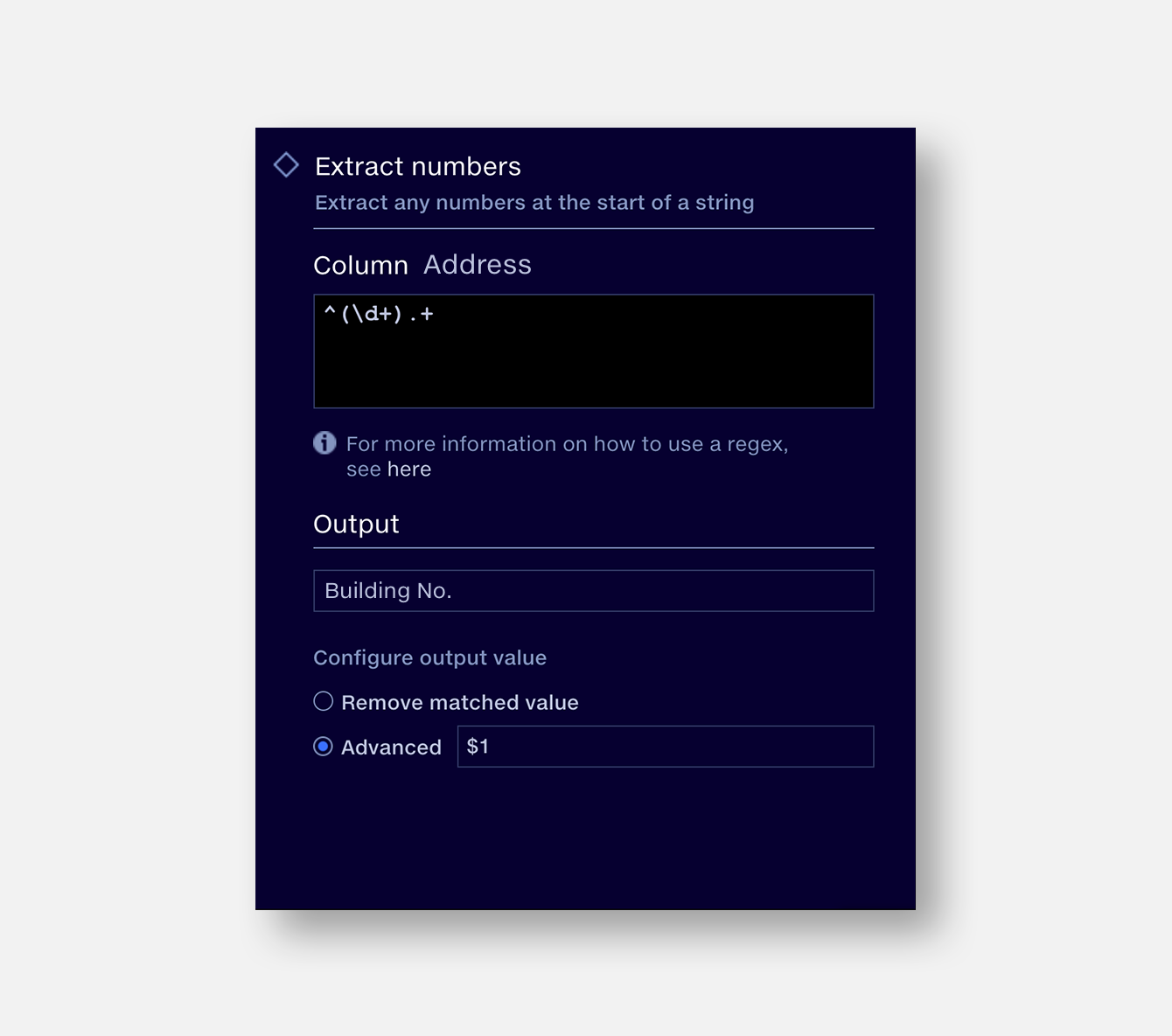
We want to strip out non-alphanumeric characters, such as punctuation or symbols, to help standardise a list of company names. This regex looks any characters that are not words, whitespaces or digits and removes them.
[^\w\s\d]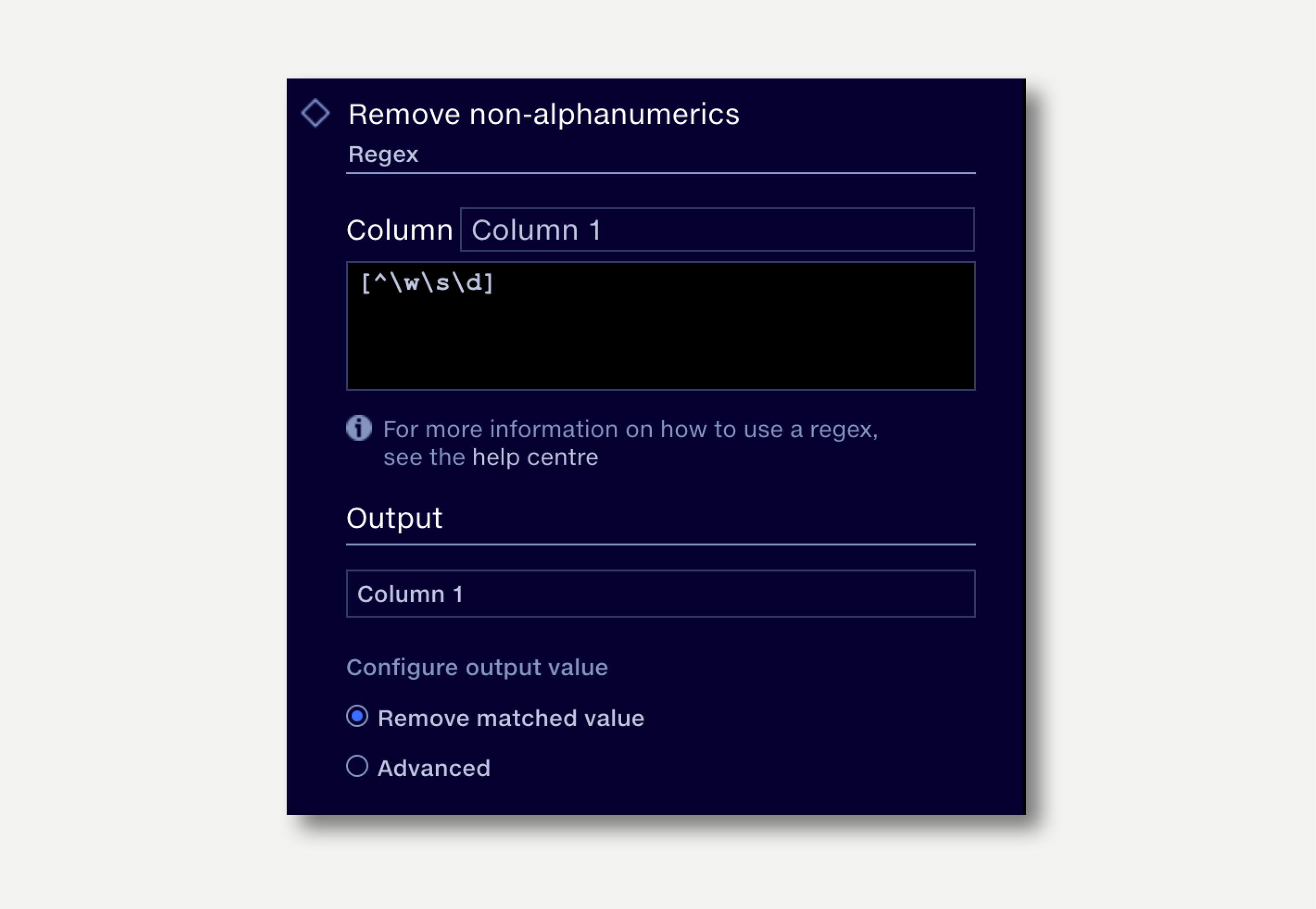
In a list of company names, where initials are separated by a space, we want to remove the space. This regex looks for a single non-whitespace character, followed by one or more spaces. It then writes only the matched non-whitespace characters followed by the rest of the string.
\b(\S)\s+(?=\S\b)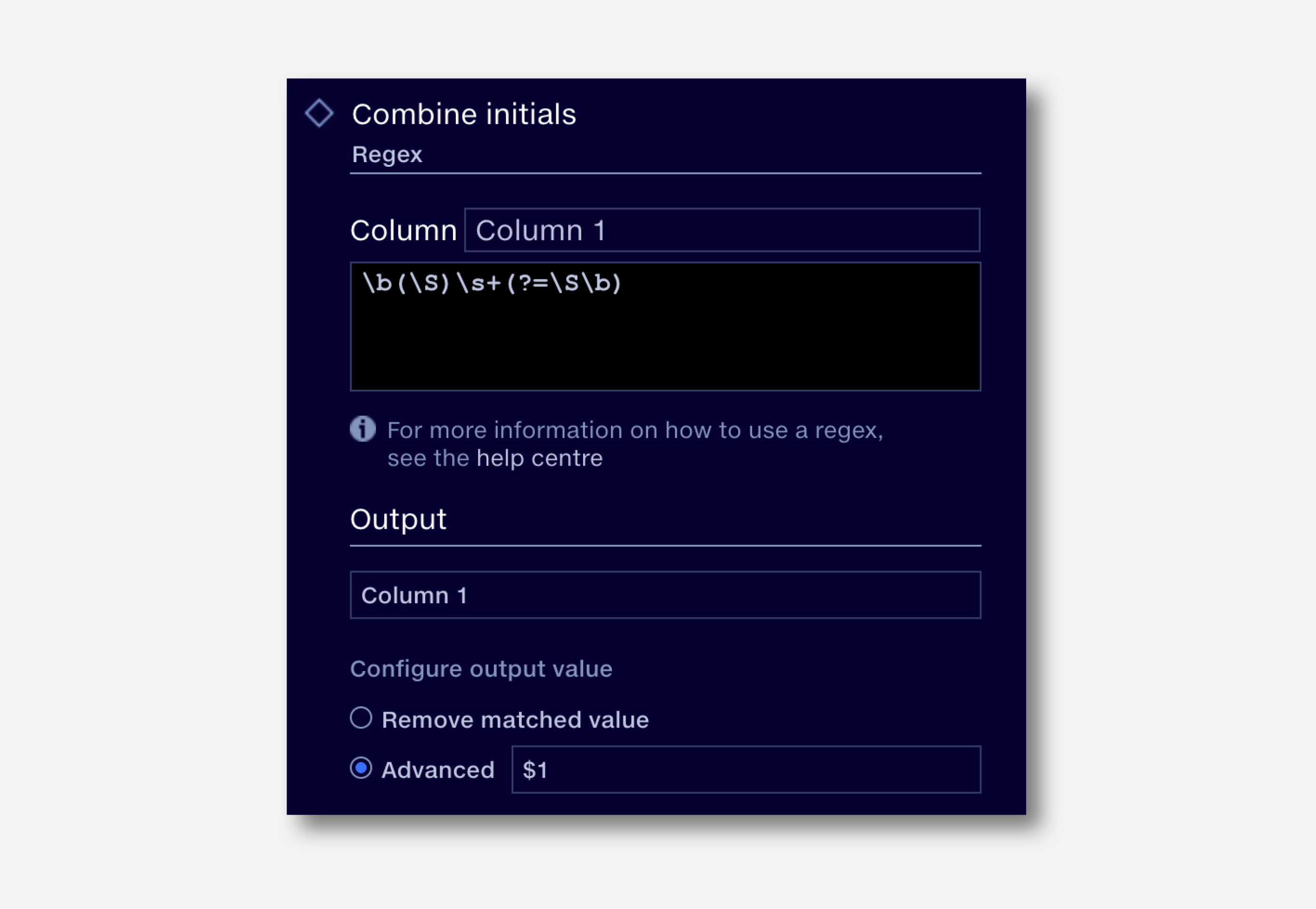
Quantemplate uses the Java version of regex. For full syntax details see the Java Regex Documentation.
Character |
Function |
Example |
| |
Or Matches either the expression before or the expression after | |
gray|grey matches either “gray” or “grey” |
( ) |
Grouping |
gray|grey and gr(a|e)y both match “gray” or “grey” |
[ ] |
Matches a single character that is contained within the brackets |
[abc] matches “a”, “b”, or “c”gr[ae]y matches “gray” or “grey”, but not “graey”, “graay”, etc.[a-z] specifies a range which matches any lowercase letterfrom “a” to “z” [abcx-z] matches “a”, “b”, “c”, “x”, “y”, or “z”[hc]at matches “hat" and “cat”[a.c] matches only “a”, “.”, or “c” |
[^ ] |
Matches a single character that is not contained within the brackets |
[^abc] matches any character other than “a”, “b”, or “c”[^a-z] matches any character that is not a lowercase letterfrom “a” to “z” [^b]at matches all strings matched by .at except “bat”q[^x] matches “qu” in “question”. It does not match “Iraq” since there is no character after the q for the negated character class to match |
{n} |
Preceding item is matched exactly n times |
a{3} matches only “aaa”[1-9][0-9]{3} matches a number between 1000 and 9999 |
{min,} |
Preceding item is matched min or more times |
a{3,} matches “aaa”, “aaaa”, “aaaaa”, “aaaaaa”, etc.a{3,5} matches “aaa”, “aaaa” and “aaaaa” |
{min,max} |
Preceding item is matched at least min times, but not more than max times |
a{3,5} matches only “aaa”, “aaaa” and “aaaaa”.[1-9][0-9]{2,4} matches a number between 100 and 99999 |
. |
Matches any character |
a.c matches “abc”, “acc”, “adc”, etc.gr.y matches “gray”, “grey”, “gr%y”.at matches any three-character string ending with “at”, including “hat”, “cat”, and “bat” |
? |
Matches the preceding character zero or one times |
ab?c matches “ac”, “abc”colou?r matches “color” and “colour”[hc]?at matches “hat”, “cat”, and “at” |
* |
Matches the preceding character zero or more times |
ab*c matches “ac”, “abc”, “abbc”, “abbbc”, etc.s.* matches “s” followed by zero or more characters, for example: “s” and “saw” and “seed”[hc]*at matches “hat”, “cat”, “hhat”, “chat”, “hcat”, “cchchat”, “at”, etc. |
+ |
Matches the preceding character one or more times |
ab+c matches “abc”, “abbc”, “abbbc”, but not “ac”[hc]+at matches “hat”, “cat”, “hhat”, “chat”, “hcat”, “cchchat”, etc. but not “at” |
^ |
Anchors the starting position in a string |
^[hc]at matches “hat” and “cat”, but only at the beginning of the string |
$ |
Anchors the ending position in a string |
[hc]at$ matches “hat” and “cat”, but only at the end of the string |
\ |
Escaped Treats the escaped character as a literal rather than a regex command |
\[.\] matches any single character surrounded by “[” and “]” since the brackets are escaped, for example: “[a]” and “[b]”1\+1=2 matches “1+1=2” |
Character |
Function |
\d |
Any digit |
\D |
Not a digit |
\w |
Any word character (Alphahnumeric characters, plus the underscore “_”) |
\W |
Not a word character |
\s |
Whitespace character (tab, carriage return, space, etc.) |
\S |
Not a whitespace |
\A |
First character in a string |
\z |
Last character in a string |
\u |
Uppercase letters |
\l |
Lowercase letters |
\p |
Visible characters and the space character |
\b |
Word boundaries |
\B |
Non-word boundaries |
Character |
Function |
x |
The character x |
\\ |
The backslash character |
\t |
The tab character |
\r |
The carriage-return character |
\e |
The escape character |
Regex101.com
Easy-to-use syntax testing environment for regular expressions.
Java Regex Documentation
Full documentation of the Java Regex version used by Quantemplate.
Java Regular Expressions Tester
Another environment to test the validity and output of a regular expression, including output group replacement functionality.