Data in Quantemplate resides in the data repo – an area for your cleansed data, along with any reference datasets. Data can be uploaded directly to the repo or cleansed and exported from your pipelines.
Data can shared or downloaded from your pipelines. Filtered and pivoted datasets from your data repo can be downloaded via Analyse.
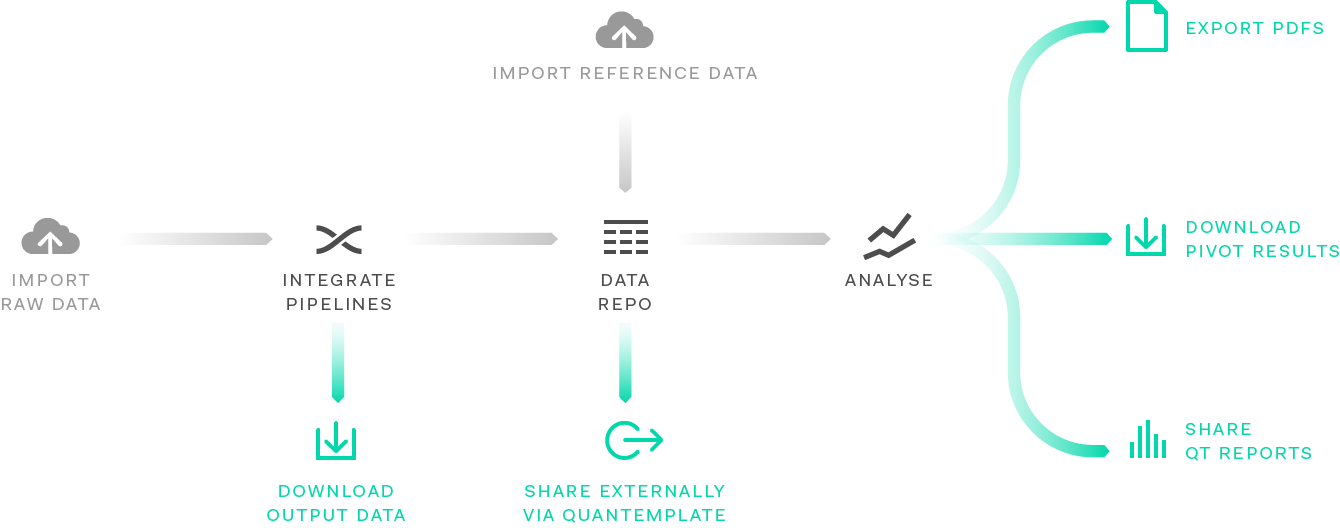
To use data in Quantemplate Analyse, it must first be
imported to your data repo.
There are two paths for importing data:
The data repo is a storage area for clean datasets and reference data. Datasets with a single row of headers can be uploaded directly to the data repo. The upload process will ignore any blank rows above or below the data, or blank columns either side of the data. The first line of data will be interpreted as column headers. Read more about uploading data.
Datasets which require cleansing, structuring or combining should be imported and processed via Pipelines, then exported to the data repo.
Quantemplate supports XLS, XLSX and CSV files. Large CSV files may be compressed with GZip to reduce upload times.
The Report Data Source allows you to load, filter and synchronise dataset for every Pivot frame in the report. New Pivot frames use the report Data Source by default.
Add filters to your report data source to save time setting filters on each Pivot individually.
The dataset preview shows the first first 1000 rows of filtered data.
By default, a pivot table uses the report data source. This can be overridden within a pivot table by editing the table’s data source. Filters applied in a pivot table apply on top of the filters in a report data source. For more details see Create a pivot and filtering.
To export the filtered dataset used in your report, click the download button on the top right of the report filter. Data will be downloaded in CSV format, UTF-8 with Byte Order Mark, for compatability with Excel. The CSV delimiter can be changed, in order to support different regional number formatting settings in Excel. Read more about download file formats here.
To export pivoted and filtered data from a pivot table, click the download button.